A chihuahua in an astronaut suit floating in the universe, cinematic lighting, glow effect.
A deer walking in a snowy field.
A fox running in a forest clearing.
A swan floating gracefully on a lake.
A knight riding a horse on a race course.
A panda walking and munching bamboo in a bamboo forest.
A corgi running on the grassland on the grassland.
A leaf falling gently from a tree.
A horse galloping through a meadow.
A barrel floating in a river.
A bald eagle flying in the blue sky.
A helicopter hovering above a cityscape.
Abstract
Diffusion model has demonstrated remarkable capability in video generation, which further sparks interest in introducing trajectory control into the generation process. While existing works mainly focus on training-based methods (e.g., conditional adapter), we argue that diffusion model itself allows decent control over the generated content without requiring any training. In this study, we introduce a tuning-free framework to achieve trajectory-controllable video generation, by imposing guidance on both noise construction and attention computation. Specifically, 1) we first show several instructive phenomena and analyze how initial noises influence the motion trajectory of generated content. 2) Subsequently, we propose FreeTraj, a tuning-free approach that enables trajectory control by modifying noise sampling and attention mechanisms. 3) Furthermore, we extend FreeTraj to facilitate longer and larger video generation with controllable trajectories. Equipped with these designs, users have the flexibility to provide trajectories manually or opt for trajectories automatically generated by the LLM trajectory planner. Extensive experiments validate the efficacy of our approach in enhancing the trajectory controllability of video diffusion models.
Noise resampling of initial high-frequency components
Gradually increasing the proportion of resampled high-frequency information in the frame-wise shared noises can significantly reduce the artifact in the generated video. However, this also leads to a gradual loss in trajectory control ability. A resampling percentage of 75% strikes a better balance between maintaining control and improving the quality of the generated video.
Top-left to bottom-right
Bottom-left to top-right
Top-left to bottom-right (AnimateDiff)
Trajectory control via frame-wise shared low-frequency noise
The success cases on the left demonstrate that the moving objects in the generated videos can be roughly controlled by sharing low-frequent noise across the bounding boxes of the given trajectory. However, the precision of control and success rate remains somewhat constrained, as evidenced by the failure instances on the right.
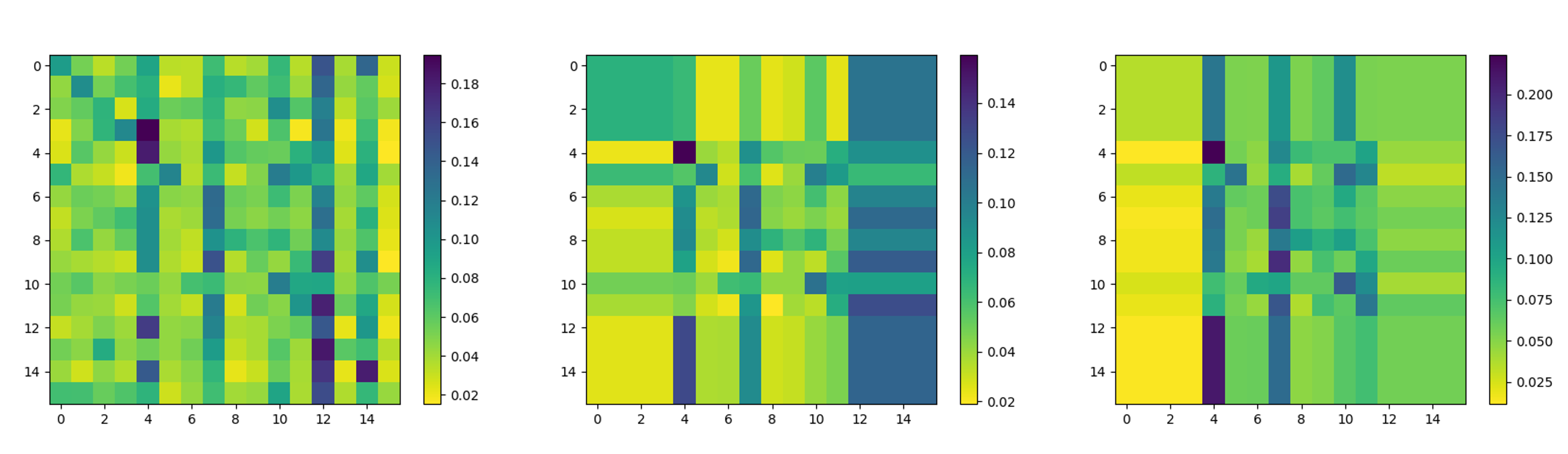
Attention isolation in temporal dimension
Compared to normal sampling for initial noises (left), partial repeated sampling will lead to significant attention isolation in the temporal dimension and bring strong artifacts (mid). When calculating the attention weights received by isolated frames, manually splitting a portion of attention weights from isolated frames to other frames will remove artifacts (right).
Comparisons of trajectory control
Results with short movements
Ablation results
Longer video generation
Larger video generation
BibTex
@misc{qiu2024freetraj,
title={FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models},
author={Haonan Qiu and Zhaoxi Chen and Zhouxia Wang and Yingqing He and Menghan Xia and Ziwei Liu},
year={2024},
eprint={2406.16863},
archivePrefix={arXiv}
}