SemanticAdv: Generating Adversarial Examples via Attribute-conditioned Image Editing
3The Chinese University of Hong Kong 4University of Illinois Urbana-Champaign 5Uber ATG
* The first three authors contributed equally.
Abstract
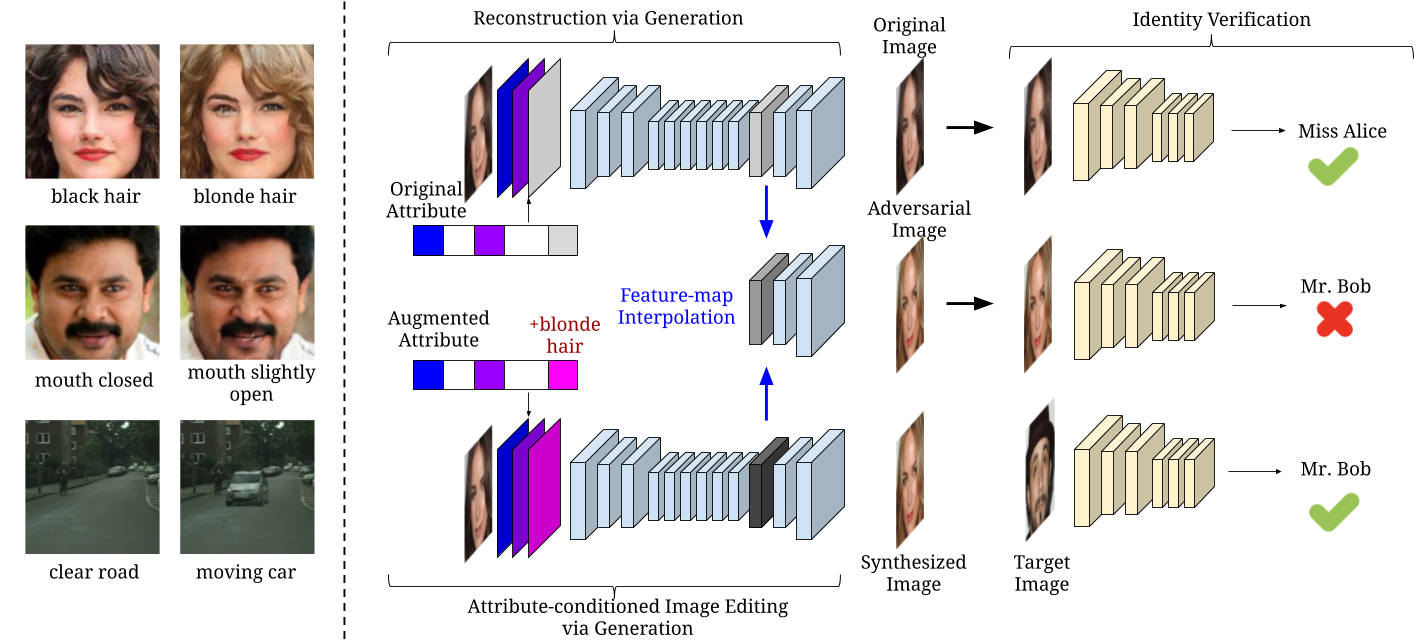
Recent studies have shown that DNNs are vulnerable to adversarial examples which are manipulated instances targeting to mislead DNNs to make incorrect predictions. Currently, most such adversarial examples try to guarantee “subtle perturbation” by limiting the Lp norm of the perturbation. In this paper, we propose SemanticAdv to generate a new type of semantically realistic adversarial examples via attribute-conditioned image editing. Compared to existing methods, our SemanticAdv enables fine-grained analysis and evaluation of DNNs with input variations in the attribute space. We conduct comprehensive experiments to show that our adversarial examples not only exhibit semantically meaningful appearances but also achieve high targeted attack success rates under both whitebox and blackbox settings. Moreover, we show that the existing pixel-based and attribute-based defense methods fail to defend against SemanticAdv. We demonstrate the applicability of SemanticAdv on both face recognition and general street-view images to show its generalization. We believe that our work can shed light on further understanding about vulnerabilities of DNNs as well as novel defense approaches. Our implementation is available at https://github.com/AI-secure/SemanticAdv.
Code and Models
 Codes |
Citation
@inproceedings{qiu2019semanticadv,
title={Semanticadv: Generating adversarial examples via attribute-conditioned image editing},
author={Qiu, Haonan and Xiao, Chaowei and Yang, Lei and Yan, Xinchen and Lee, Honglak and Li, Bo},
booktitle={ECCV},
year={2020}
}